Lokale KI in Pentesting und Sicherheitsforschung: Befreiung oder Kostenfalle?
KI-Modelle wie ChatGPT, Claude oder Gemini sind aus dem Arbeitsalltag vieler IT-Fachkräfte nicht mehr wegzudenken. Code generieren, Dokumentation zusammenfassen, Konzepte erarbeiten. Die Einsatzgebiete sind breit. Doch wer in der offensiven IT-Sicherheit arbeitet, stößt mit Cloud-basierten KI-Diensten schnell an Grenzen. Nicht an technische, sondern an praktische, rechtliche und ethische.
Das Thema lokale KI beschäftigt unsere Branche zunehmend. In diesem Beitrag wollen wir die Argumente dafür und dagegen ehrlich einordnen und eine Diskussion anstoßen: Wie haltet ihr es mit lokaler KI in der Sicherheitsforschung?
Warum Cloud-KI für Pentester ein Problem ist
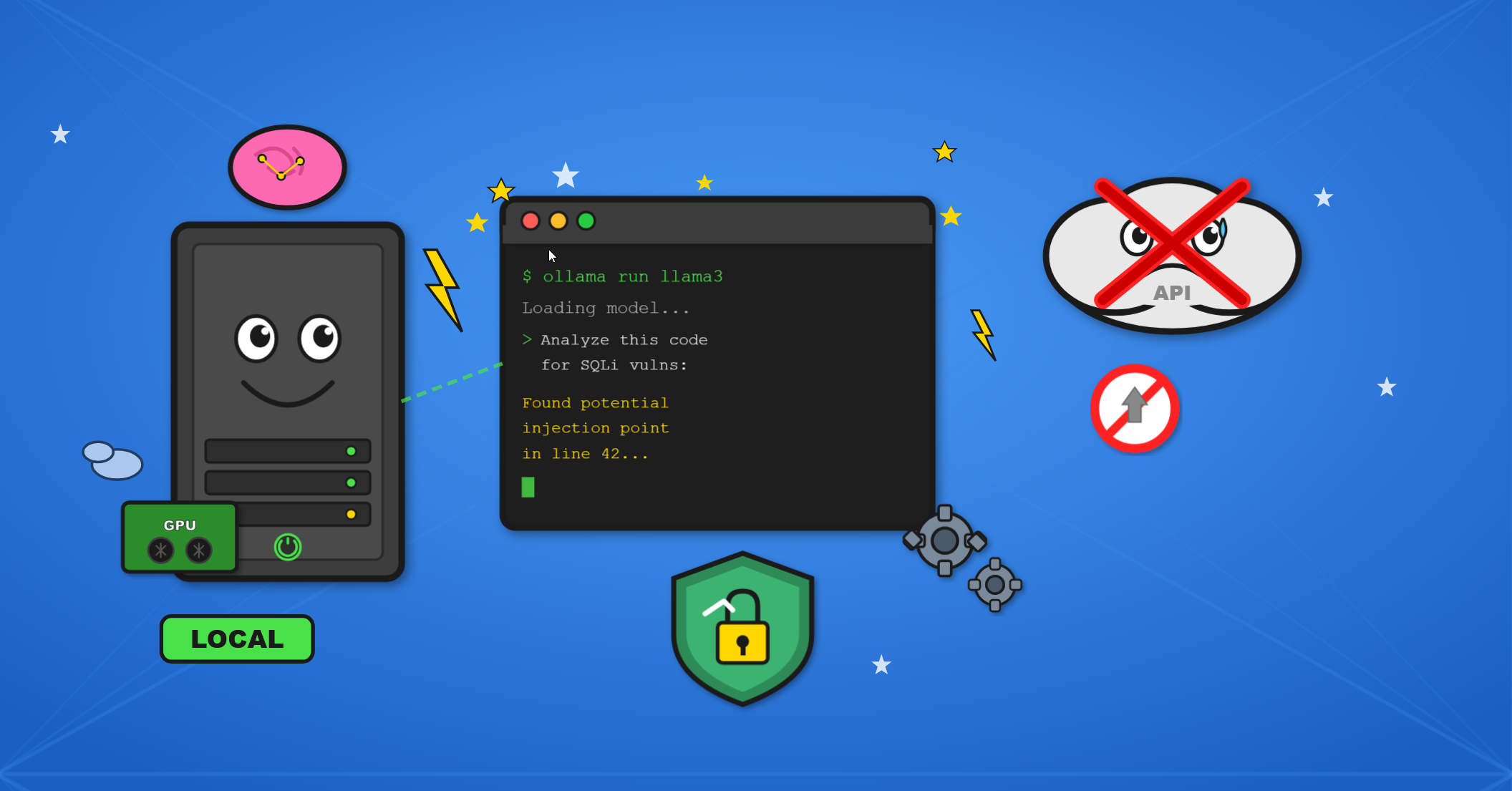
Wer Penetration Tests oder Red-Team-Engagements durchführt, arbeitet zwangsläufig mit sensiblen Kundendaten. API-Dokumentationen, Quellcode, Netzwerkdiagramme, interne Konfigurationen. All das darf nicht in die Cloud eines KI-Anbieters geladen werden. Nicht nur weil es vertraglich problematisch wäre, sondern weil es ein Vertrauensbruch gegenüber dem Kunden wäre. Egal wie gut die Datenschutzrichtlinien eines Anbieters formuliert sind: Das Risiko, dass Daten für das Training verwendet oder durch Sicherheitslücken exponiert werden, lässt sich nie vollständig ausschließen.
Dazu kommt ein ganz praktisches Problem: Cloud-basierte KI-Modelle weigern sich, Schadcode zu generieren. Das klingt zunächst vernünftig. Für eine IT-Sicherheitsfirma, die genau diesen Code für autorisierte Angriffe benötigt, ist es jedoch ein erhebliches Hindernis. Wer einen funktionierenden Reverse-Shell-Payload oder ein Phishing-Template für ein Red-Team-Engagement braucht, muss ChatGPT und Co. davon überzeugen auhorisiert zu sein oder gibt vor grade an einem CTF (Capture The Flag) Tunier Teilzunehmen.
Was lokale KI leisten kann
Digitaler Sparringspartner
Einer der wertvollsten Einsatzzwecke ist die Nutzung als Sparringspartner. Steckt man bei der Analyse einer Webanwendung fest, kann man dem Modell den relevanten Codeabschnitt zeigen und gemeinsam Hypothesen entwickeln. Wo könnte eine Race Condition vorliegen? Gibt es eine unzureichende Input-Validierung, die man übersehen hat? Die KI ersetzt dabei nicht das eigene Denken, aber sie kann blinde Flecken aufdecken und als zweites Paar Augen fungieren.
Unterstützung in DFIR
Auch in der digitalen Forensik und Incident Response steckt echtes Potenzial. Logdateien parsen, Artefakte aus Speicherabbildern korrelieren, Zeitlinien aus verschiedenen Quellen zusammenführen. Gerade in zeitkritischen IR-Szenarien kann ein lokaler KI-Assistent den Unterschied machen. Nicht als Ersatz für Erfahrung, aber als Beschleuniger.
Code-Review und Tooling
Quellcode auf Sicherheitslücken zu prüfen ist zeitaufwändig. Lokale Modelle können große Codebases vorab analysieren und potenzielle Schwachstellen markieren. Die Trefferquote ist nicht perfekt, aber als erste Filterebene vor dem manuellen Review durchaus brauchbar. Und da der Code die eigene Infrastruktur nie verlässt, bleibt die Vertraulichkeit gewahrt.
Dazu lassen sich lokale Modelle nahtlos in eigene Toolchains integrieren. Frameworks wie Ollama oder vLLM machen den Betrieb technisch zugänglich, offene Modelle wie Llama, Mistral oder DeepSeek bieten inzwischen beeindruckende Qualität.
Digitale Souveränität
Wer sich vollständig auf Cloud-KI-Dienste verlässt, macht sich abhängig. Abhängig von Preismodellen, die sich über Nacht ändern können. Abhängig von Terms of Service, die bestimmte Anwendungsfälle plötzlich ausschließen. Und abhängig von geopolitischen Entscheidungen. Exportrestriktionen können dazu führen, dass ein Dienst für bestimmte Länder oder Branchen schlicht nicht mehr verfügbar ist.
Lokale Modelle schaffen hier Unabhängigkeit. Einmal heruntergeladen und konfiguriert, laufen sie auch dann weiter, wenn ein Anbieter seine Richtlinien ändert. Und was lokal verarbeitet wird, bleibt lokal. Kein Logging durch Dritte, keine Möglichkeit, dass Eingaben in zukünftigen Trainingsläufen auftauchen.
Die andere Seite: Kosten und Grenzen
Hardware
Leistungsfähige lokale Modelle brauchen leistungsfähige Hardware. Wer ein 70B-Parameter-Modell flüssig betreiben will, braucht GPUs mit ausreichend VRAM. Eine einzelne professionelle GPU kostet leicht mehrere tausend Euro, und für wirklich große Modelle braucht man unter Umständen mehrere davon. Gerade jetzt, wo Hardwarepreise durch steigende Nachfrage nach AI-Beschleunigern weiter anziehen, ist das eine erhebliche Investition.
Kleinere Modelle im 7B- bis 14B-Bereich laufen zwar auch auf Consumer-Hardware, liefern aber nicht immer die Qualität, die man für komplexe Aufgaben braucht.
Qualität und Aufwand
Auch wenn offene Modelle enorme Fortschritte gemacht haben: In bestimmten Bereichen liegen die großen Cloud-Modelle noch vorn. Die Lücke wird kleiner, aber sie existiert. Dazu kommt der Aufwand für Einrichtung, Updates und Evaluierung neuer Modellversionen. Das kostet Zeit und setzt Know-how voraus.
KI ersetzt keine Forscher
KI ersetzt kein eigenes Denken. Wer blind auf KI-generierte Ergebnisse vertraut, ohne sie zu validieren, wird früher oder später auf die Nase fallen. Halluzinationen sind real, Kontext geht verloren, und ein Modell versteht die Feinheiten einer spezifischen Kundenumgebung nicht. Sicherheitsforschung erfordert Kreativität, Intuition und tiefes technisches Verständnis. Das bringt ein Sprachmodell nicht mit.
Wer KI als Werkzeug begreift statt als Ersatz, wird den größten Nutzen daraus ziehen.